Mplusのモンテカルロ法の結果を整形する関数
Categories:
要約
Mplusのモンテカルロ法の書く繰り返しのパラメータや適合度を整形する関数を書きました。Mplusの.outファイルのパスと各パラメータが保存されたテキストファイルのパスを引数に渡して使います。
extract_montecarlo(filename="mplus.out", represult = "represults.txt")
次のように,ヘッダー付きのデータフレームを出力します。
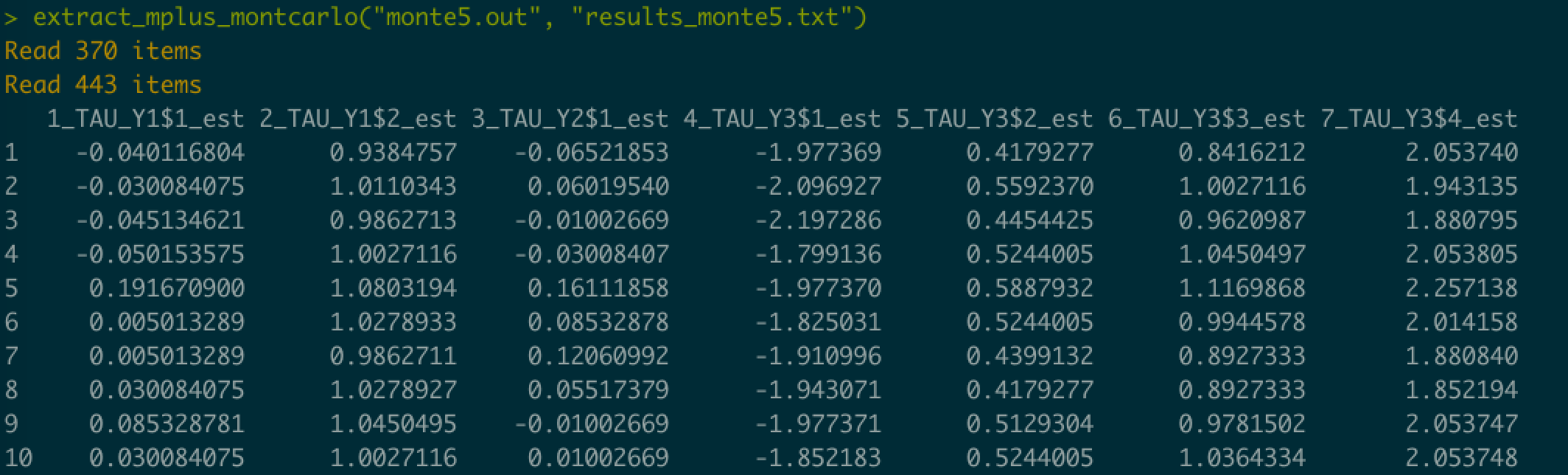
使いたい人がいるかはわかりませんが,一番最後にコードを置いておきます。
問題
Mplusでモンテカルロ法を用いる場合には,MONTECARLOコマンドのオプションでRESULTS = results_monte5.txt;のように書くと各繰り返しのパラメータの推定値や適合度が記録されます。生成されたファイルは次のような見た目をしています。
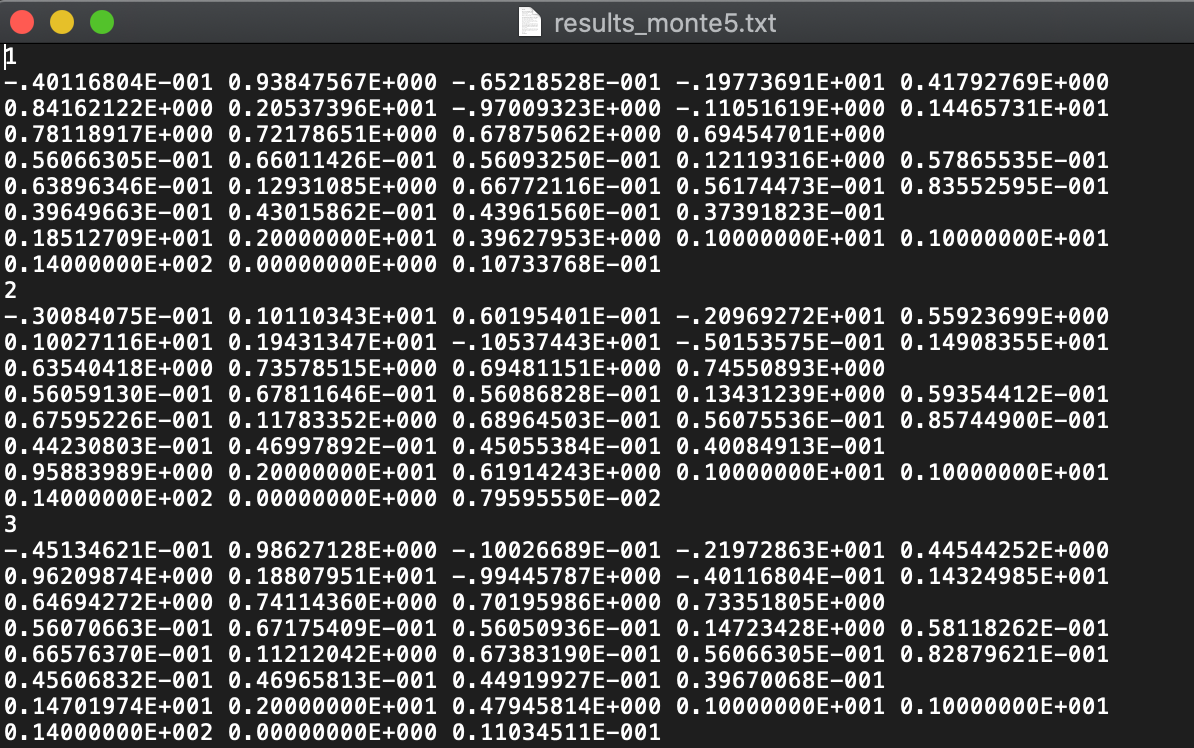
それぞれの数字が何を表しているかは,.outファイルの最後の方に書いてあります。
RESULTS SAVING INFORMATION
Order of data
Replication number
Parameter estimates
(saved in order shown in Technical 1 output)
Standard errors
(saved in order shown in Technical 1 output)
Chi-square : Value
Chi-square : Degrees of Freedom
Chi-square : P-Value
CFI
TLI
Number of Free Parameters
RMSEA : Estimate
SRMR
Save file
results_monte5.txt
Save file format Free
要するに,繰り返しの番号ごとにブロックが区切られていて,パラメータの推定値,パラメータの標準誤差,適合度等という順番に並んでいるのですが,パラメータの順番についてはTechnical 1 outputにある順番で並べてあると書いてあります。Technical outputには推定したパラメータに番号がふられています。先ほどの結果のパラメータはこの番号順に並んでいる訳です。普通のMplusの解析だとOUTPUTコマンドにTECH1を指定すると表示されるようですが,MONTECARLOコマンドを使うと自動で表示されるようです。
TECHNICAL OUTPUT
PARAMETER SPECIFICATION
TAU
Y1$1 Y1$2 Y2$1 Y3$1 Y3$2
________ ________ ________ ________ ________
1 2 3 4 5
TAU
Y3$3 Y3$4 Y4$1 Y4$2 Y4$3
________ ________ ________ ________ ________
6 7 8 9 10
NU
Y1 Y2 Y3 Y4
________ ________ ________ ________
0 0 0 0
MplusAutomationのパッケージにlookupTech1Parameterという関数があり,パラメータ番号を指定するとそれがどのパラメータなのかを教えてくれるのですが,MONTECARLOコマンドで表示されるTECHNICAL OUTPUTはTECH1で表示させたものとは別物として扱われて,うまく扱えませんでした。
この情報をうまくまとまった形で取り出す方法がありそうなものですが,Mplusのユーザーマニュアルをざっとみた感じ見つからなかったので仕方なしに関数を自分で書くことにしました。
関数
reshape_montecarlo_resultsというデータの形を整える関数と,.outファイルからパラメータと適合度のラベルを取得するobtain_headerという2つの関数を組み合わせてextract_mplus_montecarloという関数を構成しています。とりあえず動けば良いという精神のもと作ったので,さまざまなSEMでちゃんと動くかは試していません。その内試すかもしれません。
library(stringr)
reshape_montecarlo_results <- function (filename="") {
x <- scan(filename, what = character())
rep_index <- which(nchar(x)<6) # replicationは整数値だから文字数は多くとも3-4ぐらいまで
num_rep <- as.integer(x[rep_index][length(rep_index)]) # 何回整数値が出たかで繰り返し数を判断
num_val <- rep_index[2] - rep_index[1] - 1 # 整数値の間の要素の数を数えて行列の列にする
res <- data.frame(matrix(as.numeric(x[-1*(rep_index)]), nrow = num_rep, ncol = num_val, byrow = TRUE))
res
}
obtain_header <- function(filename = "") {
x <- scan(filename, what = character(), sep = "\n", blank.lines.skip = F)
parameter_specpart <- x[which(str_detect(x, pattern = "PARAMETER SPECIFICATION")):
which(str_detect(x, pattern = "STARTING VALUES"))]
## パラメータのセクションがあるかを確認
TAUincluded <- any(str_detect(parameter_specpart, pattern = "TAU"))
LAMBDAincluded <- any(str_detect(parameter_specpart, pattern = "LAMBDA"))
THETAincluded <- any(str_detect(parameter_specpart, pattern = "THETA"))
divide_into_block <- function (x) {
dividingline <- c(which(str_detect(x, pattern = "________")) - 1, length(x))
num_block <- length(dividingline) - 1
divided <- list()
for (i in 1:num_block) {
part <- x[dividingline[i]:(dividingline[i+1]-2)]
divided[[i]] <- part
}
divided
}
get_varnames_over_underscore <- function(x) {
temp <- x[which(str_detect(x, pattern = "________")) - 1]
varnames <- unlist(str_split(temp, pattern = " "))[unlist(str_split(temp, pattern = " ")) > 0]
varnames
}
find_parameters <- function (x) {
temp <- which(str_detect(x, pattern = "\\s\\d|\\s\\d\\d")) # パラメータ番号が書いてある行を見つける
temp <- unlist(str_split(x[temp], pattern = " ")) # 空白で分割
temp[temp >= 0]
}
split_and_remove_null <- function (x) {
temp <- str_split(x, pattern = " ")
temp <- lapply(temp, function (y) {y[y >= 0]})
temp
}
fill_zero <- function (x) {
num_max <- max(sapply(x, length))
lapply(x, function (y) {c(y, rep("0", num_max - length(y)))})
}
## TAUの部分の処理
tau_res <- character()
if (TAUincluded) {
tau <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "TAU"))[1]:which(str_detect(parameter_specpart, pattern = "NU"))[1]]
divided <- divide_into_block(tau)
for (i in 1:length(divided)) {
varnames <- get_varnames_over_underscore(divided[[i]])
parameterno <- find_parameters(divided[[i]])
tau_res <- c(tau_res, str_c(parameterno, "_TAU_", varnames))
}
}
## NUの部分の処理
nu_res <- character()
nu <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "NU"))[1]:
which(str_detect(parameter_specpart, pattern = "LAMBDA"))[1]]
divided <- divide_into_block(nu)
for (i in 1:length(divided)) {
varnames <- get_varnames_over_underscore(divided[[i]])
parameterno <- find_parameters(divided[[i]])
nu_res <- c(nu_res, str_c(parameterno, "_NU_", varnames))
}
## LAMBDAの部分の処理
lambda_res <- character()
if (THETAincluded) {
endpoint <- "THETA"
} else {
endpoint <- "ALPHA"
}
lambda <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "LAMBDA"))[1]:
which(str_detect(parameter_specpart, pattern = endpoint))[1]] #全部カテゴリカルだとTHETAなしの場合があるためALPHA
divided <- divide_into_block(lambda)
for (i in 1:length(divided)) {
names_lv <- get_varnames_over_underscore(divided[[i]])
lines_including_param <- divided[[i]][which(str_detect(divided[[i]], pattern = "\\s\\d|\\s\\d\\d"))]
parameterno <- split_and_remove_null(lines_including_param)
lambda_res <- c(lambda_res, unlist(lapply(parameterno, function (x) {
names_ov <- x[1]
str_c(x[2:length(x)], names_lv, "_BY_", names_ov)
})))
}
## THETAの部分
theta_res <- character()
if (THETAincluded) {
theta <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "THETA"))[1]:
which(str_detect(parameter_specpart, pattern = "ALPHA"))[1]]
divided <- divide_into_block(theta)
for (i in 1:length(divided)) {
varnames_col <- get_varnames_over_underscore(divided[[i]])
lines_including_param <- divided[[i]][which(str_detect(divided[[i]], pattern = "\\s\\d|\\s\\d\\d"))]
parameterno <- split_and_remove_null(lines_including_param)
parameterno <- fill_zero(parameterno)
theta_res <- c(theta_res, unlist(lapply(parameterno, function (x) {
varnames_row <- x[1]
str_c(x[2:length(x)], varnames_row, "_WITH_", varnames_col)
})))
}
}
## ALPHAの部分の処理
alpha <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "ALPHA"))[1]:
which(str_detect(parameter_specpart, pattern = "BETA"))[1]]
alpha_res <- character()
divided <- divide_into_block(alpha)
for (i in 1:length(divided)) {
varnames <- get_varnames_over_underscore(divided[[i]])
parameterno <- find_parameters(divided[[i]])
alpha_res <- c(alpha_res, str_c(parameterno, "ALPHA_", varnames))
}
## BETAの部分の処理
beta <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "BETA"))[1]:
which(str_detect(parameter_specpart, pattern = "PSI"))[1]]
beta_res <- character()
divided <- divide_into_block(beta)
for (i in 1:length(divided)) {
names_iv <- get_varnames_over_underscore(divided[[i]])
lines_including_param <- divided[[i]][which(str_detect(divided[[i]], pattern = "\\s\\d|\\s\\d\\d"))]
parameterno <- split_and_remove_null(lines_including_param)
beta_res <- c(beta_res, unlist(lapply(parameterno, function (x) {
names_dv <- x[1]
str_c(x[2:length(x)], names_dv, "_ON_", names_iv)
})))
}
## PSIの部分の処理
psi <- parameter_specpart[which(str_detect(parameter_specpart, pattern = "PSI"))[1]:
which(str_detect(parameter_specpart, pattern = "STARTING VALUES"))[1]]
psi_res <- character()
divided <- divide_into_block(psi)
for (i in 1:length(divided)) {
varnames_col <- get_varnames_over_underscore(divided[[i]])
lines_including_param <- divided[[i]][which(str_detect(divided[[i]], pattern = "\\s\\d|\\s\\d\\d"))]
parameterno <- split_and_remove_null(lines_including_param)
parameterno <- fill_zero(parameterno)
psi_res <- c(psi_res, unlist(lapply(parameterno, function (x) {
varnames_row <- x[1]
str_c(x[2:length(x)], varnames_row, "_WITH_", varnames_col)
})))
}
## 適合度などの名前を取得
start_index <- which(str_detect(x, pattern = "Replication number")) + 5
temp <- which(str_detect(x, pattern = "Save file"))
end_index <- temp[temp > start_index][1] - 2
fit_names <- str_trim(x[start_index:end_index])
labels_param <- c(tau_res, nu_res, lambda_res, theta_res, alpha_res, beta_res, psi_res)
labels_param <- labels_param[str_detect(labels_param, pattern = "^[^0]")]
labels_param_est <- str_c(labels_param, "_est")
labels_param_se <- str_c(labels_param, "_se")
c(labels_param_est, labels_param_se, fit_names)
}
extract_mplus_montecarlo <- function (outfile = "", represult ="") {
dat <- reshape_montecarlo_results(represult)
colnames(dat) <- obtain_header(outfile)
dat
}