RからeStatのAPIを使ってみる
Categories:
Rからe-StatのAPIを使ったときのメモ.以下のサイトの言う通りにやってみただけ.
https://qiita.com/nozma/items/f88f5cc60ab63461deae
e-StatのアプリケーションIDの取得
使うためには,アプリケーションIDというものを取得しないとならない.
https://www.e-stat.go.jp/api/api-info/api-guide
上のサイトの指示通りに,ユーザー登録してマイページよりアプリケーションIDを発行する.
認証情報の管理
keyringというパッケージを使うと,ソースコードの中にIDとか書かなくてすむらしい.便利.
https://qiita.com/nozma/items/9f4a638906471d125e96
特別支援学校高等部の進路
試しに,文科省の「学校基本調査」から特別支援学校高等部で知的障害の進路の情報をとって,グラフにしてみたのがこちら.統計表をダウンロードしてからdplyrを使って整形していく流れ.実際の数と割合をグラフにしてみた.
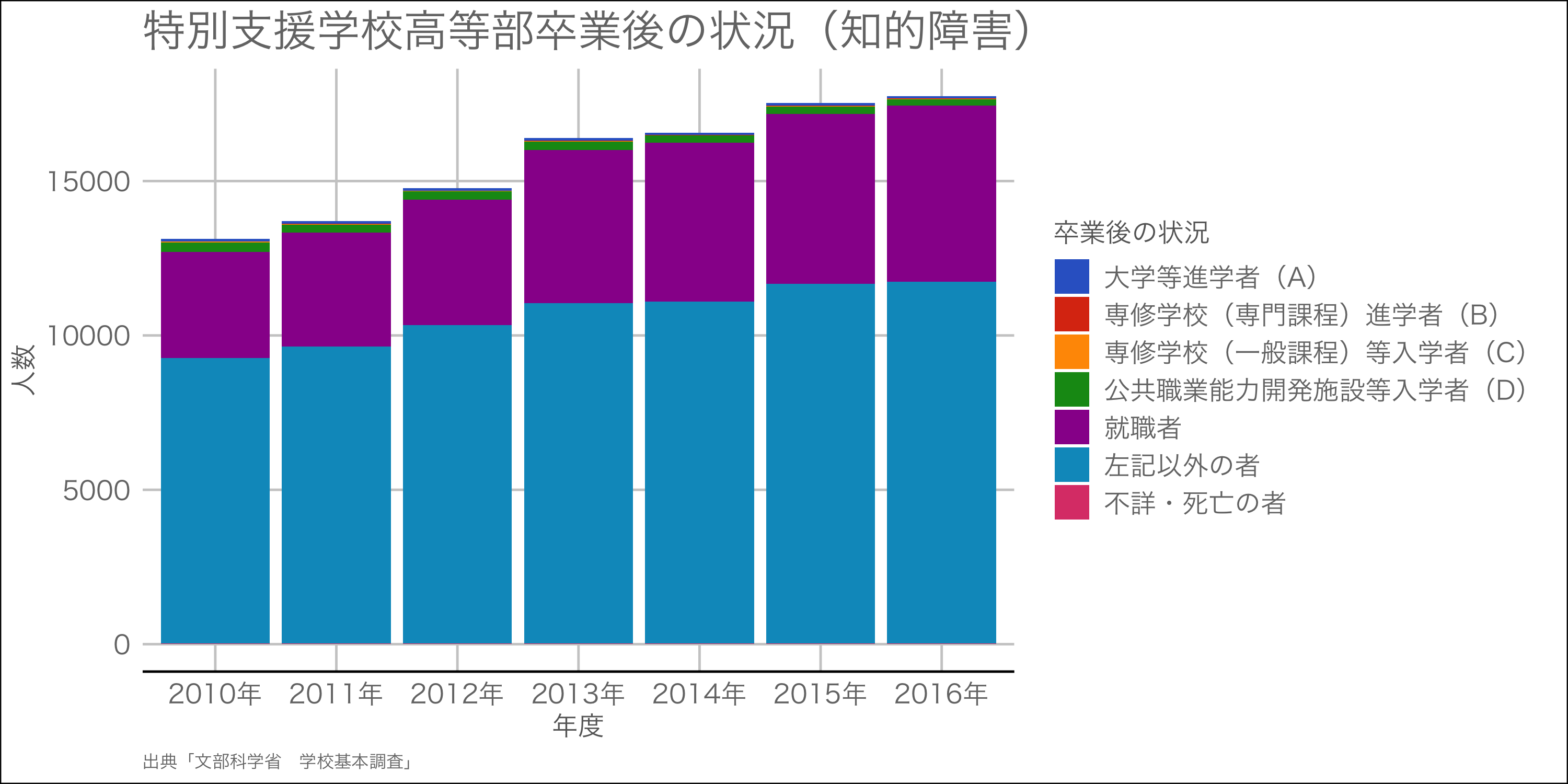
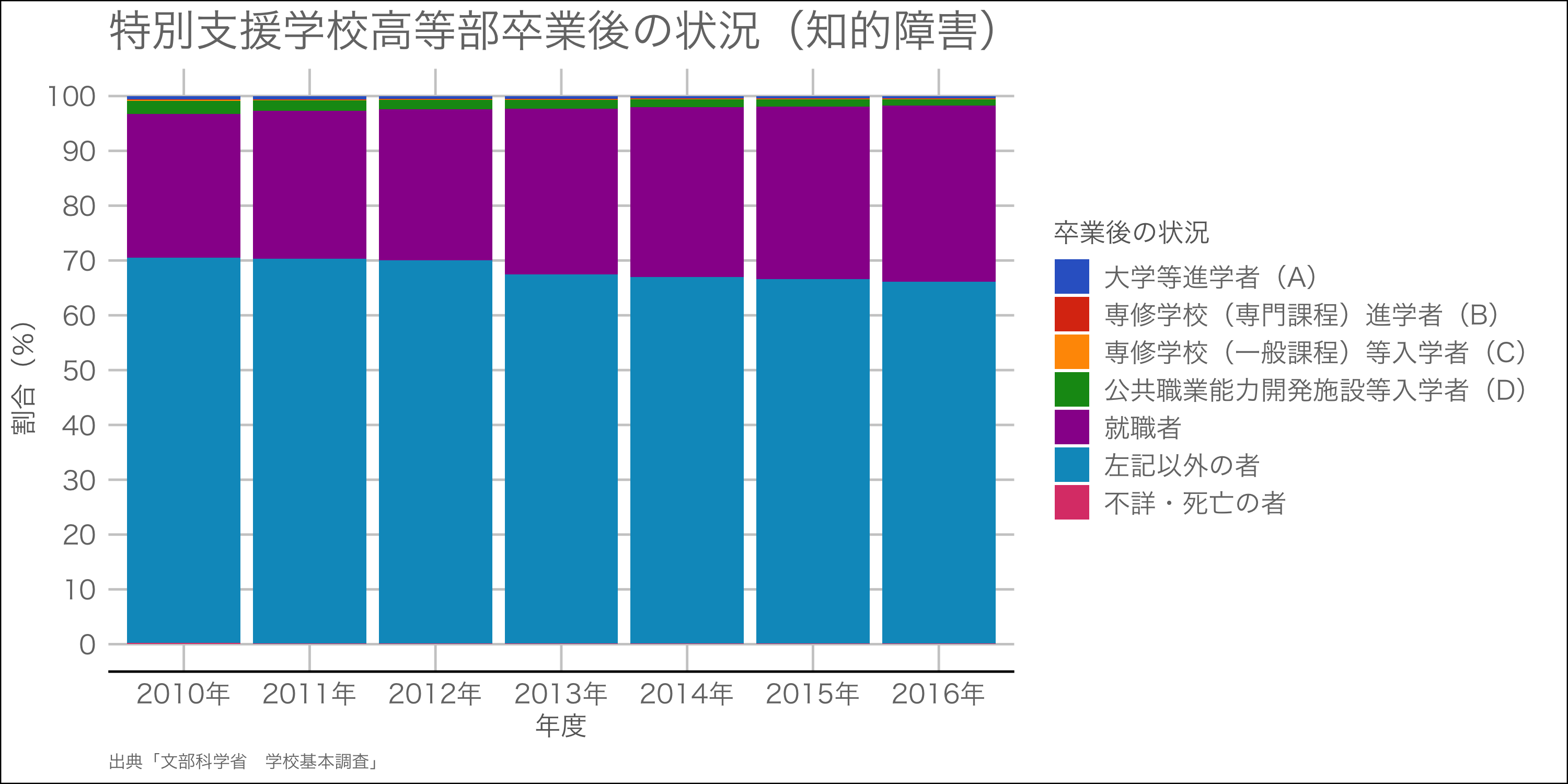
使ったコードは以下のもの.なぜか平成23年度から25年度はひとまとまりで提供されていたり,平成22年度とそれ以降で列名が違ったりと下処理が面倒くさかったです.
library(pacman)
p_load(keyring, httr, listviewer, rlist, pipeR, dplyr, stringr, ggplot2, stringi,
readr, ggthemes)
keyring::key_set("e-stat")
## 統計表を検索してお目当ての表を特定
response <- GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/json/getStatsList",
query = list(
appId = keyring::key_get("e-stat"),
searchWord = "障害種 AND 状況別 AND 高等部"
)
)
res_content <- content(response)
jsonedit(res_content)
id_table <- res_content$GET_STATS_LIST$DATALIST_INF$TABLE_INF %>>%
list.select(
id = `@id`,
year = STATISTICS_NAME_SPEC$TABULATION_SUB_CATEGORY1,
table_name = TITLE_SPEC$TABLE_NAME) %>>%
list.stack()
id_list <- pull(id_table, id)
res <- tibble()
for (id in id_list){
dat_year <- GET(
url = "https://api.e-stat.go.jp/rest/2.1/app/getSimpleStatsData",
query = list(
appId = keyring::key_get("e-stat"),
statsDataId = id
)
)
content_year <- content(dat_year)
dat_year <-read.csv(text = sub('(?s).*"VALUE"\n', "", content_year, perl = TRUE))
dat <- dat_year %>%
rename("disability" = contains("障害種"),
"sex" = contains("性別"),
"path" = contains("状況"),
"year"=contains("年次")) %>%
mutate(path=as.character(path)) %>%
filter(disability=="知的障害") %>%
filter(!str_detect(sex, "男" )) %>%
filter(!str_detect(sex, "女" )) %>%
filter(!str_detect(path,"再掲")) %>%
filter(!str_detect(path, "%")) %>%
filter(!str_detect(path, "除く")) %>%
filter(path !="計") %>%
mutate_if(is.factor, as.character) %>%
mutate(value=as.character(value))
if(is.null(dat$year)){dat <- mutate(dat, year="2010年")}
dat <- dat %>%
select(year ,path, value)
res<- bind_rows(res, dat)
}
res <- arrange(res, year) %>%
mutate(value=as.integer(value))
write_csv(res,"path_hs.csv")
## ここから積み上げグラフを作る
dat <- read_csv("path_hs.csv", col_types = "cci")
lev <- c("大学等進学者(A)",
"専修学校(専門課程)進学者(B)",
"専修学校(一般課程)等入学者(C)",
"公共職業能力開発施設等入学者(D)",
"就職者",
"左記以外の者",
"不詳・死亡の者")
dat_mo <- dat %>%
mutate(year=as.factor(year),path=factor(path,levels = lev))
p <- ggplot(dat_mo, aes(x=year, y=value, fill=path)) +
geom_bar(stat = "identity") +
labs(x="年度", y="人数") +
theme_gdocs(base_family="HiraKakuPro-W3") +
scale_fill_gdocs(name="卒業後の状況") +
ggtitle("特別支援学校高等部卒業後の状況(知的障害)")+
labs(caption="出典「文部科学省 学校基本調査」") +
theme(plot.caption=element_text(size=8, hjust=0,))
print(p)
ggsave("images/graduate_hs.png",p, width=10, height=5, dpi=300)
## 割合のグラフ
dat_per <- dat_mo %>%
group_by(year) %>%
mutate(total = sum(value)) %>%
mutate(percent=round(100*(value/total),3))
br <- seq(0,100, 10)
p1 <- ggplot(dat_per, aes(x=year, y=percent, fill=path)) +
geom_bar(stat = "identity") +
scale_y_continuous(breaks=br) +
labs(x="年度", y="割合(%)") +
theme_gdocs(base_family="HiraKakuPro-W3") +
scale_fill_gdocs(name="卒業後の状況") +
ggtitle("特別支援学校高等部卒業後の状況(知的障害)") +
labs(caption="出典「文部科学省 学校基本調査」") +
theme(plot.caption=element_text(size=8, hjust=0,))
print(p1)
ggsave("images/graduate_hs_per.png",p1, width=10, height=5, dpi=300)